Welcome to our new blog focusing on all things related to the Windows Search Platform, also known over the years as Windows Desktop Search, the Indexing Service, WSearch, and the Content Indexer. This is the first post in what will be a 4-part series covering the technology’s background and history including the evolution of the indexing service over time, the settings and configuration when you first install Windows, and the basics on what the Indexing Service does, what it provides, and how to make the most of your index.
List of posts in the series
Whether you’re a Windows expert, hardcore developer, you’re writing your first app, or you just bought your first PC, we hope that you find these posts informative and engaging. We believe with the deep history of the search platform, where we’re at today, and where we’re taking the technology that there will be something in this blog for everyone.
- The Evolution of Windows Search
You Are here
- Windows Search Configuration and Settings
- What’s in my index?
- How to make the most of search on Windows
29 years ago….
Back in the early 90’s, Microsoft was working on a technology called project Cairo (1991). Believe me, at this point in my life I had no idea that I’d eventually be working at Microsoft, or better yet working on a part of Windows that was carried forward from ideas formed and written prior to Windows ’95. Inside of Cairo was a piece of technology called the Object File System, later known as WinFS. The idea behind it was to make sense out of all the bytes of data in the filesystem in a human readable and searchable way, organized as a collection of objects with properties all part of a strongly typed schema.
Back then applications didn’t understand all the file types that were being created. There was .pdf, .html, .gif, .jpeg and many, many others. Everyone wrote to files in their own format that was easy to understand by their application and no one else. This worked fine at the time – your Adobe application opened your PDFs, internet browsers opened your html files, and photo applications opened your .gif and .jpg files. When the indexing service came along it was designed to understand these different file types and make the data inside of them searchable across the system and all applications for quick, and efficient access.
Over the course of these 29 years the service has evolved into what is the backend for a lot of Windows experiences, as well as a handful of developer APIs and their applications.
Windows NT 4.0 (1996)
The indexing service (Index Server 2.0) was introduced as part of an option-pack for Internet Information Services (IIS) in Windows NT 4.0 to perform content indexing of web server pages. This enabled users to search for text on web pages that were being hosted on an IIS server. The default location for these pages was C:\Inetpub, and that was one of the first folders the indexing service looked for content.
Filters
The concept of Filters was also introduced for the first time, allowing for the extraction of text-based content from different file types to be written into the indexing service. These filters were a way for an application to register themselves with a given file extension that the indexing service would invoke to grab the content to be put in the index when processing that file. This “processing” over the years is commonly referred to as indexing.
Have you ever cracked open a .PDF file in notepad? Do you have any idea what the below data means? What if I told you there was a way to find a PDF on your system with some specific text in it without having to browse your entire OneDrive collection?
Blindly opening a file like the above is not a very useful way to process this data for the purpose of searching, nor does it make much sense to me. This is what the indexing service would see to extract data from without the appropriate filter. Filters became a way for a specific file format to communicate the data in that file that is valued as searchable. With an IFilter for .pdf files, sentences of text, properties, and metadata within the file are returned and stored in the indexing service – the meaningful, searchable data the user cares about.
How did applications read the index? From the beginning there was an OLEDB indexing service provider that provided read-only access to the contents in the index. Using this provider applications could take advantage of the indexing service’s own version of Structured Query Lanugage (SQL) which was a strongly typed way to write code to read the data. All of these APIs are still available today for developers and applications to use.
Windows 2000 (2000)
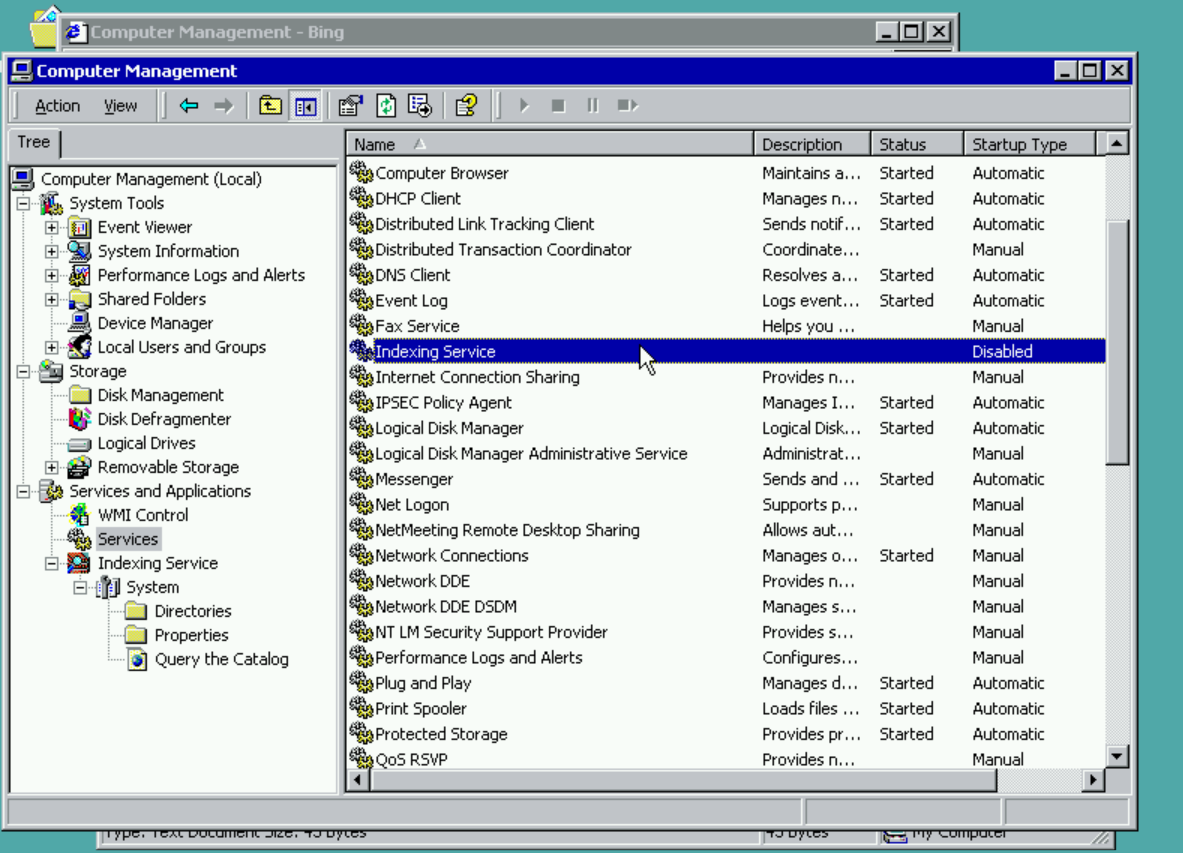
The indexing service shipped for the first time as part of the operating system with Windows 2000, however it was a Windows Component and Service that you needed to enable.
Once enabled you could configure the service to index web pages that were hosted in IIS just like in Windows NT 4.0, or local folders on the machine which had various entry points to find data such as the Management Console or File Explorer.
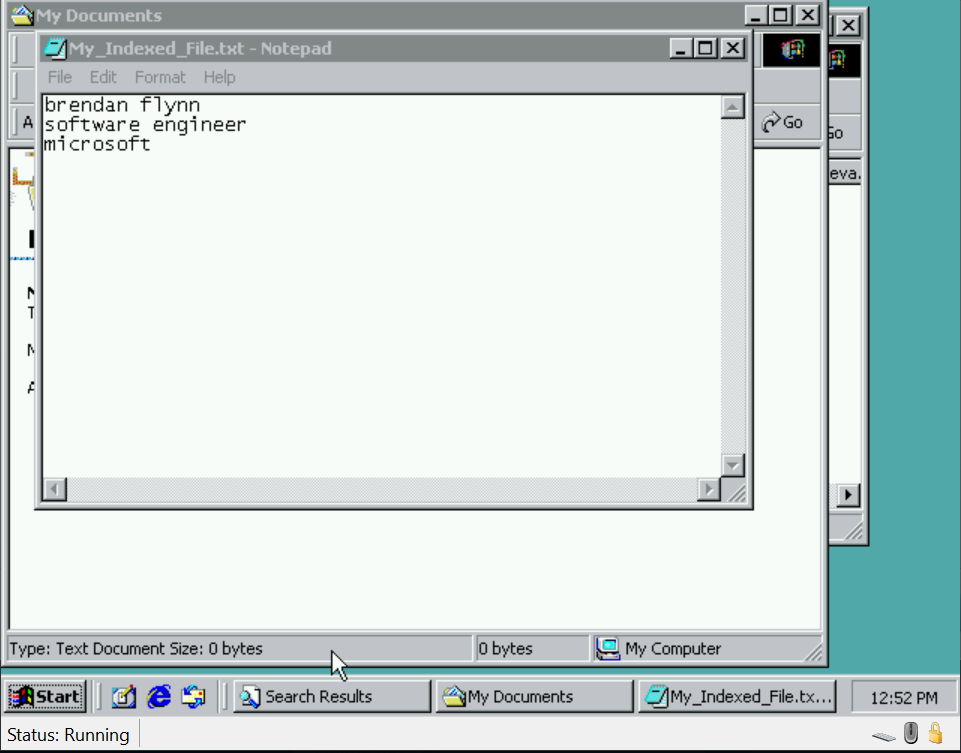
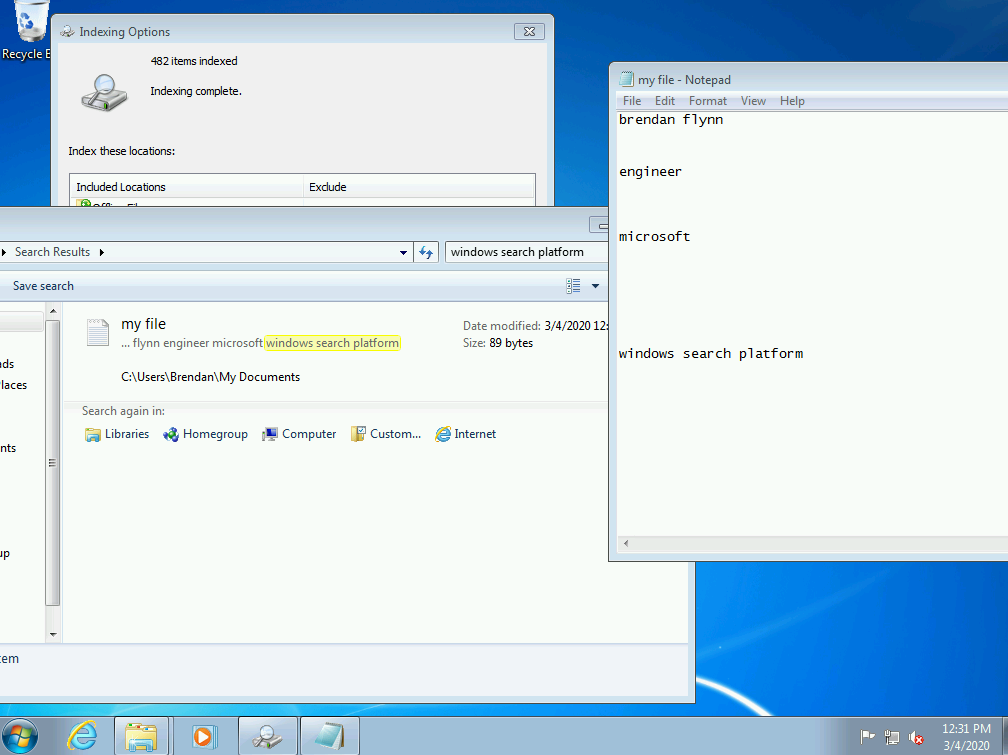
Example of creating a file with content and searching for it in Windows 2000 SP4.
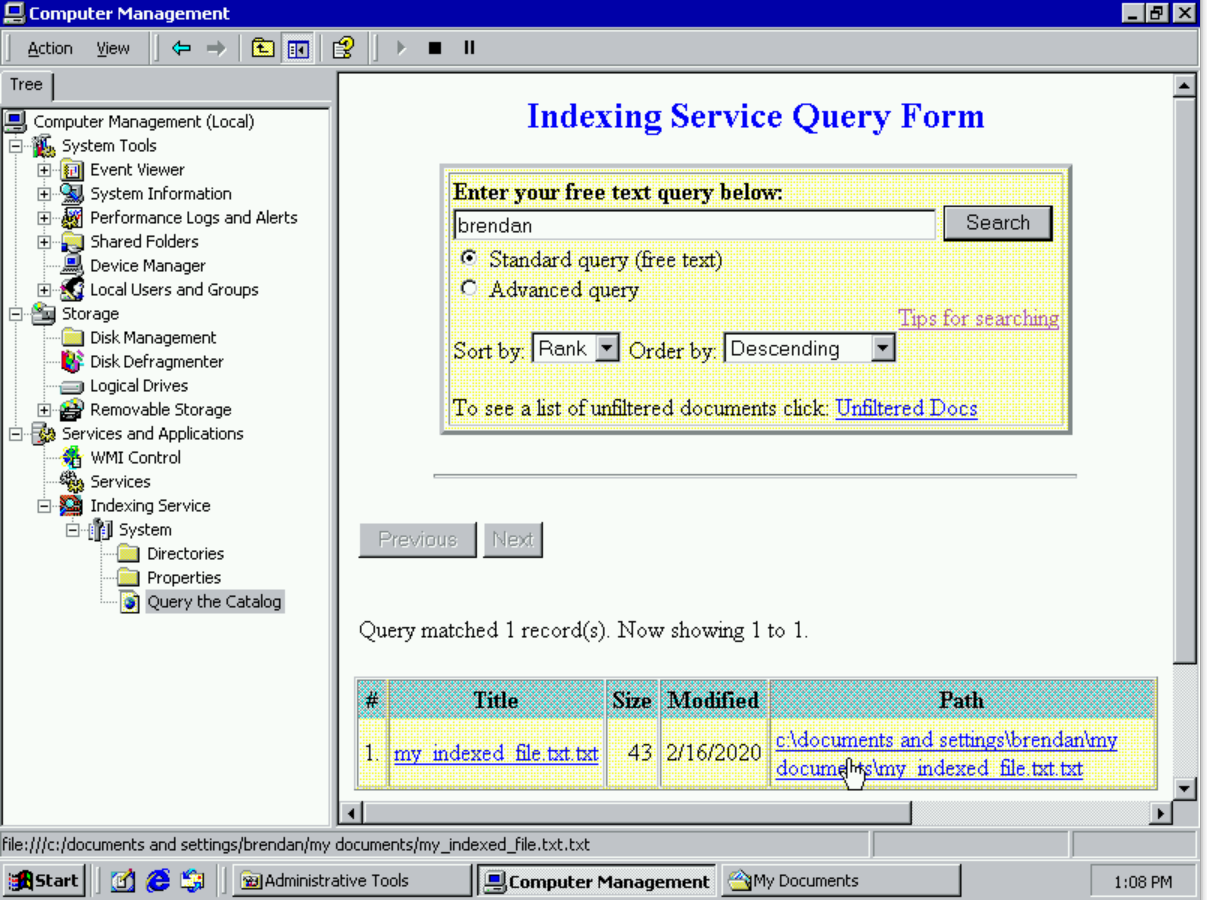
In Windows 2000 the Indexing service indexed file content. Users could then search the Indexer, and eventually find the file via the Query Form in the Management Console.
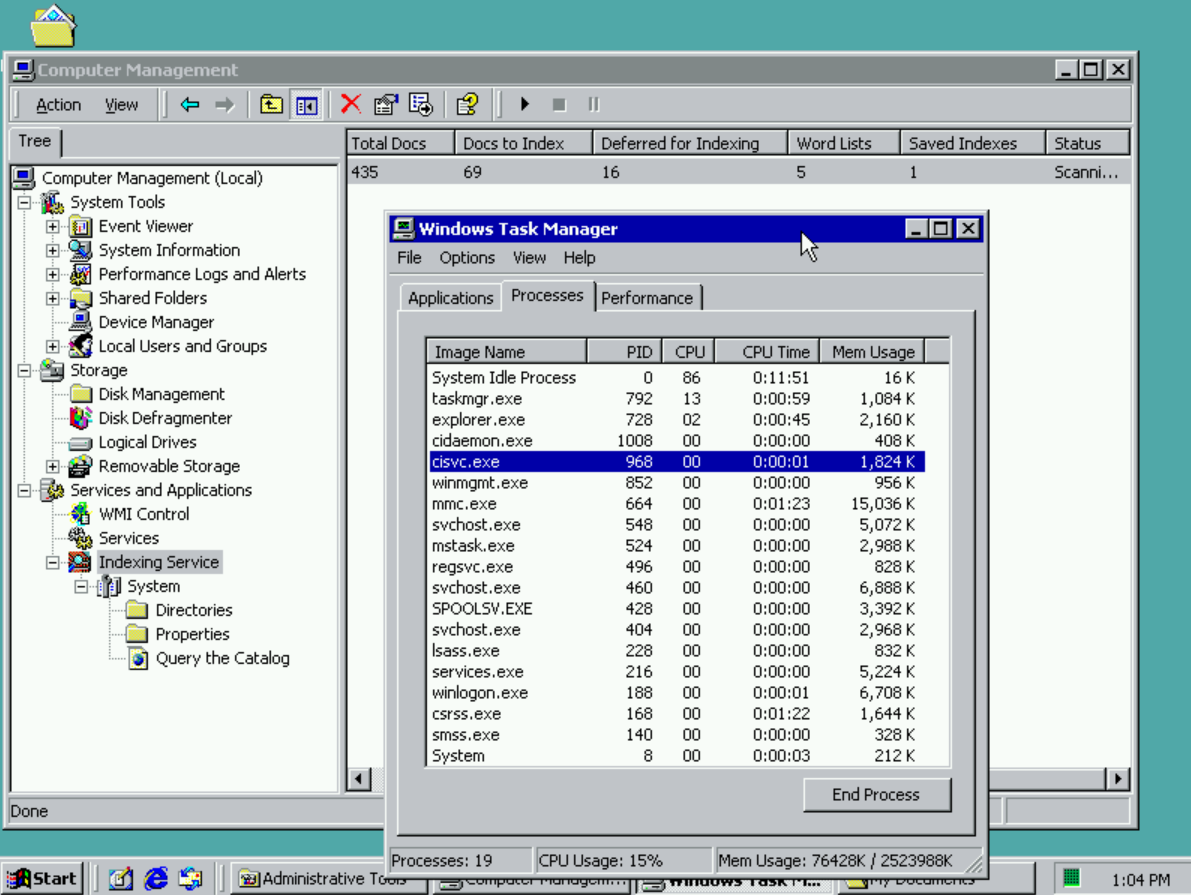
Aside from the fact that you could search items, the service also exposed various statistics to the user to understand what is happening under the covers. These statistics are the columns you see in the Computer Management UI below. Docs to Index, Deferred for Indexing, and Word Lists were just a few that existed back then. Many more continue to be added and still worked on today.
The first version of the USN journal was also released in Windows 2000 as part of NTFS 3.0. The USN Journal is a component of the file system which gave applications the ability to read all changes on any volume in the system (assuming journals were supported on that volume) and react to those changes accordingly. Processing these journal changes in order to understand when files are modified to keep the index as up to date as possible is the primary way the indexing service gets notified of file/folder changes even in Windows 10.
IFilters were also really starting to pick up with more third parties developing them to support content for unique file types to use within their applications. Popular filters at the time were the .pdf filter, as well as .gif, .jpg, .xml, .html just to name a few.
Windows XP (2001)
When Windows XP came around, the Indexing Service again shipped as part of Windows and was also enabled by default. Like all previous versions, it ran as “cisvc.exe” which stood for content indexing service.
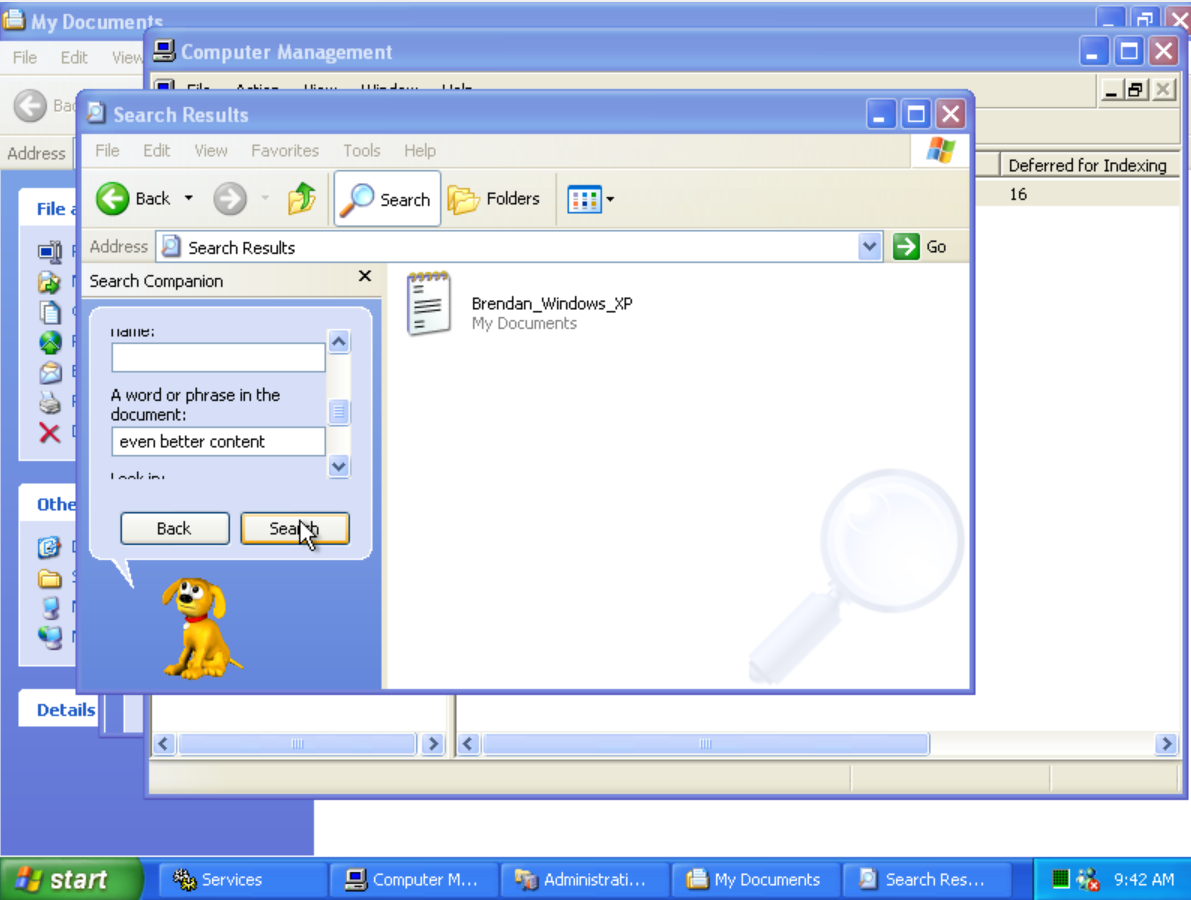
Above shows content indexing in action on Windows XP. “even better content” is a sentence in the text file Brendan_Windows_XP.txt.
Catalogs
From Windows 2000 through Windows XP, the indexing service separated the data it indexed into partitions, or catalogs.
Catalogs were a way to keep the contents of the index across different folders and paths contained and separate from one another. At first Windows 2000 and Windows XP by default supported the System catalog which stored local content and the Web Catalog which was only created and maintained if IIS was enabled on the machine. The catalogs were stored in different physical locations on the disk as well, so when IIS was uninstalled the removal of the Inetpub directory would in turn remove the appropriate web catalog and its data.
Extensibility
This release was a major one from an extensibility perspective for developers. Many new APIs were created that allowed developers to interact with the catalogs and configure options on it. Some of the more used and recognized ones are – ISearchCatalogManager/ISearchCrawlScopeManager.
Not only could your application use the APIs to configure the index, you could contribute your own data types to it as well. Originally the indexing service only knew how to process the content of files in the index as it could open every file in the same manner (NtCreateFile). Opening emails for indexing, or later on other Office or third-party data types was something that needed to be extensible and available to developers. There needed to be a way an application could tie into the system and provide its own data, whatever that might be. Developers at this time understood this gap and because of it, search protocols were born.
Applications could now create new search protocols, or different streams of content to be indexed that weren’t necessary files. Protocols were an extremely important concept because that’s what made the indexing of Outlook, Visio, SharePoint, and other data types eventually possible. It all stemmed from the Windows XP release and are actively still around today. Only Outlook knows how to process the emails it has in its’ local .pst/.ost files on the machine. Creating an interface to allow them to provide the necessary data to be indexed was crucial to onboarding many different types of data down the road.
Windows Vista (2007)
In Vista, the indexing service evolved into what is now called SearchIndexer.exe and runs as an NT system service (WSearch). There was a new control panel to configure a few options that became available directly to the user and this started to pave the way for a lot of what you still see today in Windows 10.
Starting with Vista the indexing service would index all files/folders in libraries under your user profile directory as the service was running by default when Windows started. Out of the box, this meant you could find documents you saved to these locations very quickly and efficiently. The extensibility at this point kept improving, while continuing to support the same set of APIs to query the index’s content created in Windows NT 4.0 so that applications continued to work as they always had.
Windows 7 (2009)
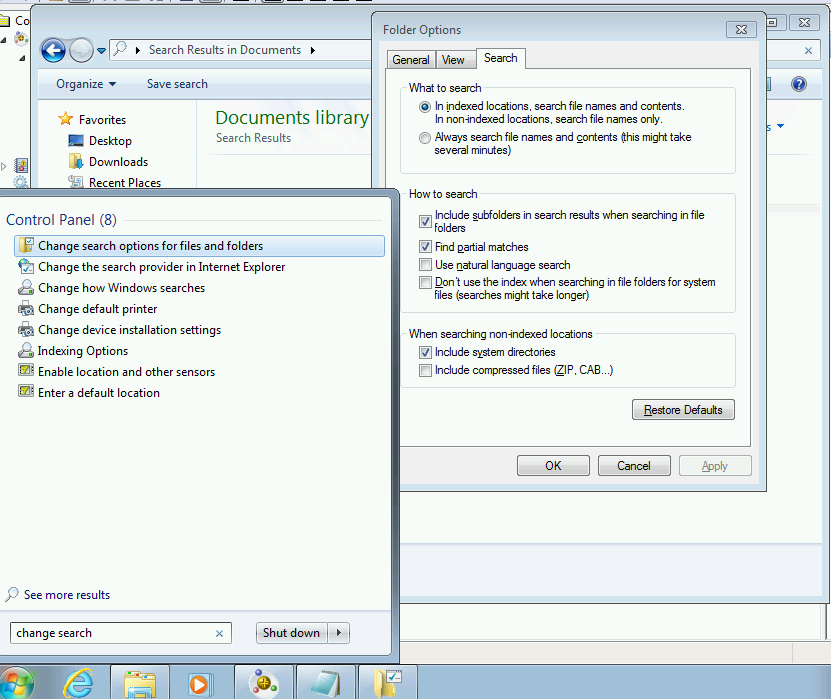
Most of the indexing features of Windows Vista went straight into Windows 7. By default, the indexing service indexed all files and folders under your user profile, but it did not index contents of all the files on your machine. This was something had to be turned on by the user. There was a new dialog in the Control Panel named Change search options for files and folders that you could use to fine tune how search worked on your machine. This directly impacted the behavior of the indexing service and how it handled your files.
Once you turned on “Always search file names and contents” in the folder options search tab you had to wait a little bit for the service to re-index the content of all the files currently stored by the indexing service. Afterwards you could start searching for content in the start menu and file explorer search bar to find any of your important documents by just typing in a few words contained inside your files.
The service in Windows 7 also kept track of where certain words were in the files so that Windows’ components such as file explorer above could highlight those occurrences on screen.
Windows 8/8.1 (2012)
Unlike Windows 7, in Windows 8 the indexing of the content of your files in your user profile was turned on by default. Searching was very easy in Windows 8 as you could just start typing and it would automatically enter in your criteria and search across settings files and apps all at the same time.
Windows 10 (2015)
Windows 10 contains the latest version of the Search Indexer, with added support to run on many different types of devices.
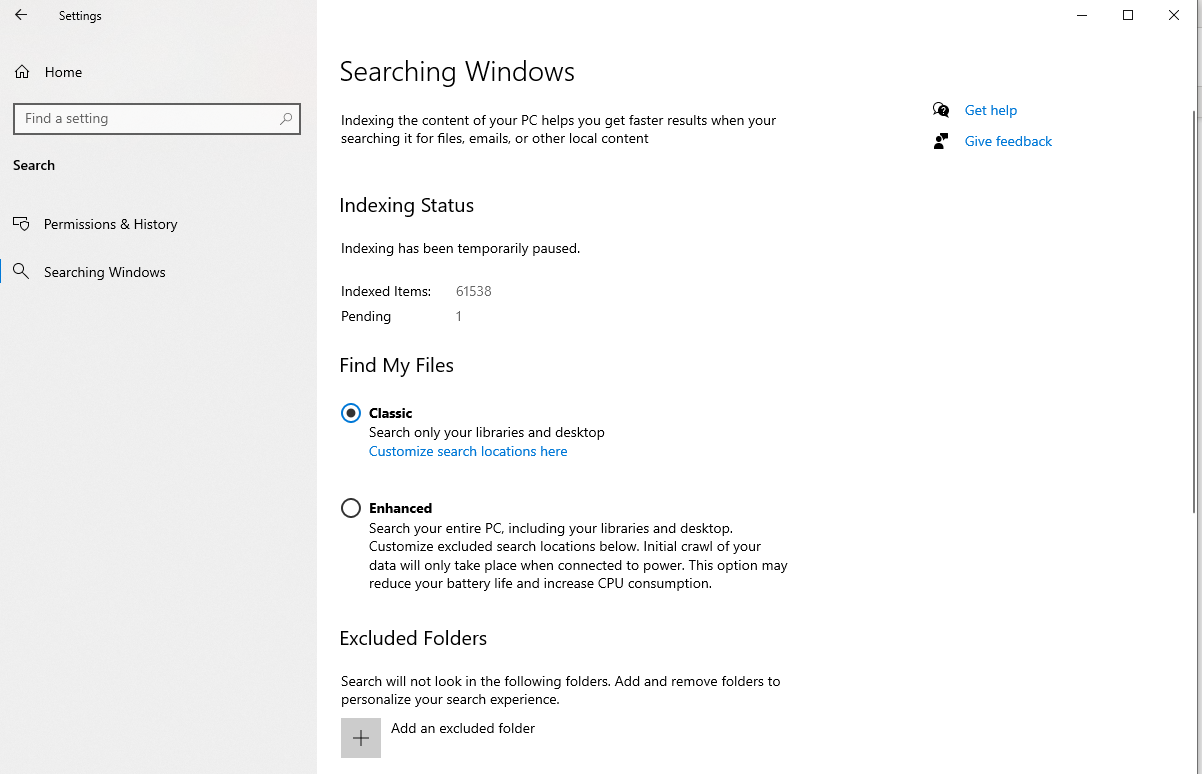
A new settings page was introduced in the Settings application from the store to highlight different options of the search indexer that weren’t exposed before. We’re going to do a much more detailed settings and configuration walkthrough in the next post, but I will discuss a few briefly here.
Excluded Folders
You can now exclude certain folders from the index if you think those folders aren’t valuable to be indexed. This is useful for large folders in your user profile directory that would otherwise be indexed for content. Excluding files/folders that don’t contain useful content helps the performance of your system overall, and allows the index to use less space on your disk.
Enhanced Search
On top of that, there is a new Find my Files “Enhanced” mode which will crawl all other drives and folders outside of your user profile directory (besides a few system areas) for metadata only. This means you can find all of those files by file name or other basic properties, but you cannot search for them using words within the contents of the files. This makes it much faster and easier to find files by name than by searching via the filesystem alone.
Looking back, although Cairo and WinFS were never actually released, the ‘content indexing’ pieces of these technologies as they were named still live on today and have been used across many different technologies at Microsoft. While the code has been improved by many teams over the course of time, and across many different versions of Windows, it still shares a common set of interfaces for developers to use to this day.
Thanks for tuning in, next up a much more detailed look into – Windows Search Configuration and Settings.
Brendan Flynn.
Senior Software Engineer, Windows Search Platform

Source: The Evolution of Windows Search | Windows Search Platform